


.png) 手机流量卡
手机流量卡 免费领卡·号卡店铺
免费领卡·号卡店铺 关于本站
关于本站AI编程工具API接入完整指南:从零配置Codex、Claude Code与Cursor
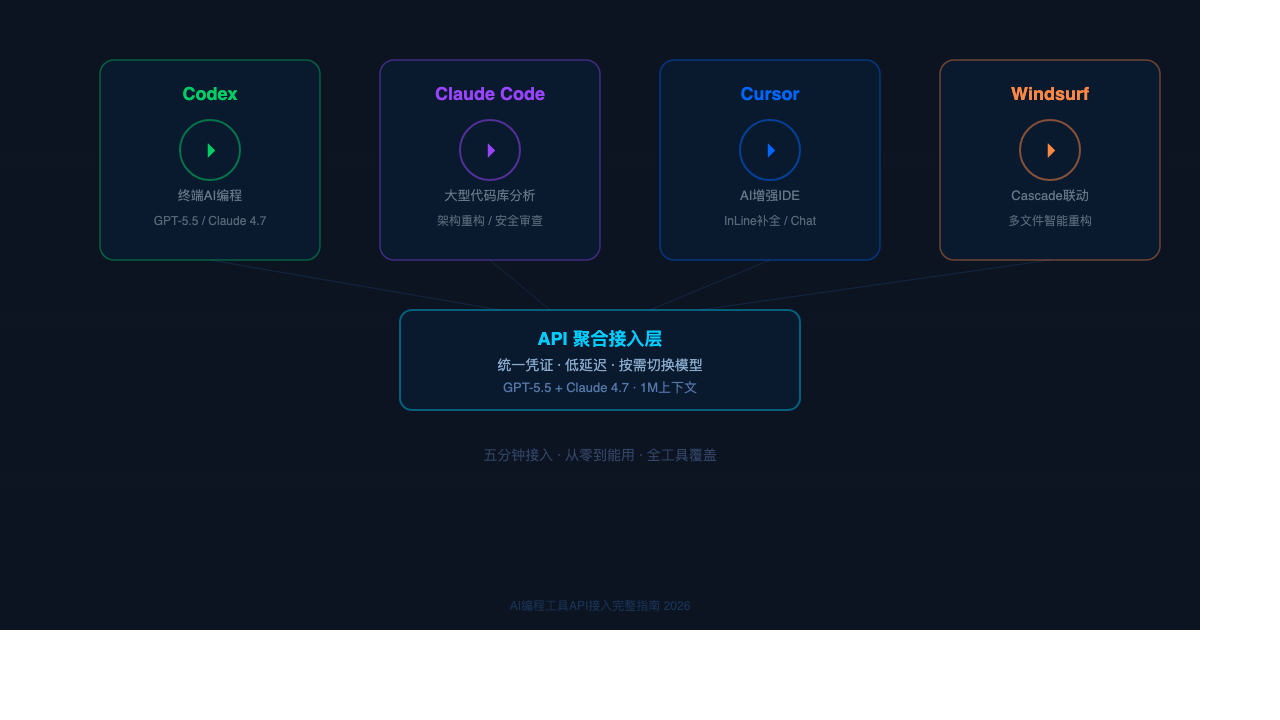
2026年,AI编程工具已经成了开发者的标准装备。但一个尴尬的现实是:很多人装了Codex、配了Claude Code、开了Cursor,却卡在API接入这一步——海外信用卡付不了、官网直连延迟高、Token消耗快得心疼。这篇文章从零开始,把AI编程工具的API接入讲清楚:选什么方案、怎么配、碰到问题怎么排查。
一、AI编程工具的API到底是怎么回事
不管是Codex、Claude Code还是Cursor,它们背后的工作原理都一样:你输入指令,工具把你的代码上下文打包成API请求,发给模型服务器,模型推理后把结果流式返回。
这个过程里有两个关键变量决定你的体验:
- 延迟:请求从你机器飞到模型服务器再飞回来的时间。国内直连海外API,这个值通常在800ms-3.8s之间。
- 费用:按Token计费。GPT-5.5和Claude 4.7的官方定价都在$15/百万Token(约¥108)。一个全职开发者一个月消耗150万Token,费用约¥135-545。
好消息是,这两个变量都可以通过选择合适的API接入方案来优化。
二、API接入方案的三种模式
模式一:官方直连
直接去OpenAI或Anthropic官网注册、绑信用卡、充值、拿Key。优点是最原生,缺点是:
- 需要外币信用卡(很多国内开发者没有)
- 延迟高(请求从国内到美国西海岸,RTT 180-350ms)
- 按零售价计费($15/百万Token)
模式二:API聚合服务
通过国内可访问的API聚合平台接入,这些平台统一采购多个模型的API额度,以更优的价格分发给终端用户。优点:
- 支持微信/支付宝直接支付,不需要外币卡
- 服务器部署在离国内更近的节点,延迟大幅降低
- 批发渠道价格,Token费用远低于官方零售
访问 api.bblabu.cn 就是一个典型的API聚合服务平台,注册后在控制台创建令牌即可获得API接入凭证。
模式三:本地代理 + 多供应商
在本地运行一个代理工具(如CC-Switch),把多个API供应商接入同一个本地端口,通过切换供应商来管理不同的模型和线路。适合同时使用多个API源的开发者。
| 模式 | 月费用(150万Token) | 首Token延迟 | 支付方式 |
|---|---|---|---|
| 官方直连 | 约¥135 | 3-5s | 外币信用卡 |
| API聚合服务 | 约¥2.5 | 1-2s | 微信/支付宝 |
| 本地代理+多源 | 约¥2.5-30 | 1-2s | 多种 |
对于大多数国内开发者,API聚合服务在费用、速度、支付便利性三个维度上都是最优解。
三、实战:从零接入Codex
第一步:注册获取API凭证
打开 api.bblabu.cn,完成注册。进入「令牌管理」,点击「添加令牌」创建一个新的API Key。建议给不同工具创建独立的令牌,方便追踪各自的消耗。
复制Key(以sk-开头的一串字符),妥善保存。
第二步:安装Codex
# 确认Node.js已安装 node --version # 通过npm安装Codex npm install -g @openai/codex # 验证安装 codex --version
第三步:配置Codex连接API
在终端中设置环境变量:
# 将以下两行添加到 ~/.zshrc 或 ~/.bashrc export OPENAI_API_KEY="sk-换成你的Key" export OPENAI_BASE_URL="https://api.bblabu.cn"
执行 source ~/.zshrc 使配置生效,然后输入 codex 即可开始使用。
第四步:验证连接
# 在Codex中测试 > 用Python写一个快速排序 # 如果正常返回代码,说明配置成功
四、实战:配置Claude Code
# 安装 npm install -g @anthropic-ai/claude-code # 配置环境变量(添加到 ~/.zshrc) export ANTHROPIC_BASE_URL="https://api.bblabu.cn" export ANTHROPIC_API_KEY="sk-换成你的Key" # 启动 claude
Claude Code启动后,输入 你好 测试连接。如果正常回复说明配置成功。
五、实战:Cursor接入自定义API
Cursor → Settings → Models → 在「OpenAI API Key」区域填入Key,勾选「Override OpenAI Base URL」填入Base URL地址,保存即可。
接入后Cursor的模型选择器中会出现GPT-5.5和Claude 4.7两个模型,可以随时切换。
六、常见问题与排查
Q1:配置后Codex报401错误
原因:Key无效或Base URL填写错误。
解决:从控制台重新复制Key(不要手动打),确认Base URL地址完整无误。
Q2:请求响应很慢
原因:网络链路问题。
解决:确认你的网络无需额外代理即可直接访问API服务器地址。如果使用VPN,尝试关闭后直连,通常延迟更低。
Q3:Token消耗太快
原因:在Codex中启用上下文压缩功能。
# ~/.codex/config.toml model = "gpt-5.5" model_context_window = 1047576 model_auto_compact_token_limit = 900000
设置后Codex会在上下文接近90万Token时自动压缩,避免每次请求都带大量历史对话。
Q4:不同工具之间如何分配Key?
建议在API控制台创建多个独立令牌,每个工具(Codex、Claude Code、Cursor)一个。这样每个工具的消耗独立追踪,某个工具的额度用完不影响其他工具。
Q5:请求偶尔超时怎么办?
可以在配置中添加备用地址。大部分API聚合服务提供多个接入点,当一个节点波动时切换到备用地址即可恢复。
七、Token消耗的优化技巧
几个实用的节省Token的技巧:
- 按任务选模型:日常编码用GPT-5.5(速度快、消耗低),复杂重构和代码审查用Claude 4.7(推理深)。不同任务的Token消耗可以差3倍以上。
- 定期清理上下文:Codex中用
/clear命令清空对话历史。长对话的上下文能占到单次请求Token的80%以上。 - 精确提问:与其说「帮我优化这个项目」,不如说「优化src/utils/helper.ts中第15-45行的性能」。精确的指令减少模型试错消耗。
- 使用上下文压缩:上面的config.toml配置就是做一个自动化的上下文管理。
八、总结
AI编程工具的API接入不是一个技术难题,而是一个选择问题。三种模式各有利弊,但对大多数国内开发者来说,API聚合服务在费用、速度和支付便利性上的综合优势是最明显的。
核心就三步:注册获取Key → 配置到工具 → 开始编码。五分钟搭好,之后就是无感的日常使用。
API费用的优化也不需要天天盯着账单——选对渠道,Token成本自然降到原来的几十分之一。把省下来的精力,花在写更好的代码上。
本文链接:https://www.kkkliao.cn/?id=3934 转载需授权!
版权声明:本文由廖万里的博客发布,如需转载请注明出处。









