


.png) 手机流量卡
手机流量卡 免费领卡·号卡店铺
免费领卡·号卡店铺 关于本站
关于本站独立开发者AI编程全链路工作流:一个人从需求到部署,API费用一毛钱
一个人、一台Mac、四个AI工具、一份API预算。从需求文档到上线部署,全链路一个人搞定——而且月API花费不超过十块钱。这是2026年独立开发者的真实工作状态。这篇文章从我的日常工作流出发,完整记录一个功能从想法到上线的全过程,包括每个环节用哪个工具、配什么模型、消耗多少Token、踩过哪些坑。
一、独立开发者的AI工具矩阵
独立开发者最大的特点不是缺技术,而是缺时间。一个人要干需求、设计、前后端、测试、运维的活。AI编程工具的价值不是「让某一步更快」,而是让一个人能干完一整个团队的活。
我当前的AI工具矩阵:
| 环节 | 工具 | 模型 | 原因 |
|---|---|---|---|
| 需求分析 | Claude Code | Claude 4.7 | 能读PRD、拆功能、发现遗漏 |
| 架构设计 | Claude Code | Claude 4.7 | 全局理解、多方案权衡 |
| 编码实现 | Codex | GPT-5.5 | 速度快、执行准确、成本低 |
| 编辑器操作 | Cursor | GPT-5.5 | Inline补全、Chat+Apply |
| 代码审查 | Claude Code | Claude 4.7 | 安全审查敏感、分析深 |
| 测试生成 | Codex | GPT-5.5 | 批量生成、速度快 |
| 部署脚本 | Codex | GPT-5.5 | DevOps命令、Docker编排 |
所有这些工具通过同一个API聚合平台接入,共用一份预算。获取API接入凭证:在 api.bblabu.cn 注册,进入「令牌管理」创建一个API Key即可,GPT-5.5和Claude 4.7两个模型都能调用。
二、实战:一个功能的全链路记录
以下是我最近开发「订单导出功能」的完整过程,记录每一个步骤的工具选择、模型决策、Token消耗和时间花费。
需求到设计:20分钟
# 在Claude Code中 > 分析项目现有的订单模块(src/api/orders.ts、src/services/order.ts), 然后规划一个「订单导出为Excel」的功能: - 支持按日期范围、订单状态筛选 - 导出字段包括订单号、用户、金额、状态、时间 - 考虑权限校验(只有管理员和订单所属用户可导出) - 给出API设计、文件结构、需要新增/修改的文件清单
Claude Code读取了现有订单代码,基于实际数据结构给出了设计方案。这一步消耗约15,000 Token,用时5分钟。
> 方案没问题,开始实施。先从数据层开始
编码实现:40分钟
切换到Codex + GPT-5.5(日常编码快且省):
# 在Codex中 > 按照刚才Claude Code的设计方案,依次实现: 1. src/services/export.ts — Excel生成逻辑,使用exceljs包 2. 在src/api/orders.ts中新增GET /orders/export接口 3. 在src/middleware/auth.ts中检查导出权限 按顺序一个一个来,做完一个告诉我再继续下一个
Codex分三步完成了实现。每步约8,000-12,000 Token,三步合计约30,000 Token。中间没有推倒重来过——因为Claude Code已经把设计做透了,Codex只需要照着执行。
测试生成:15分钟
> 为以下三个文件生成单元测试: - src/services/export.ts - src/api/orders.ts的导出接口 - 权限校验逻辑 使用Jest框架,覆盖正常场景和异常场景(无权限、空数据、超大导出量)
Codex生成了48个测试用例,其中3个需要微调(Token消耗约25,000 Token)。
代码审查:10分钟
切回Claude Code + Claude 4.7:
> 审查今天新增的导出功能的全部代码,重点: 1. 大量数据导出时是否会内存溢出(考虑使用stream) 2. 权限校验是否有遗漏(检查所有调用链) 3. 异常处理是否完整(Excel生成失败、磁盘空间不足) 4. 文件是否有清理机制
Claude Code发现了两个实际问题:大量导出时没有使用流式写入(内存会爆)、临时文件没有定时清理机制。修复后又跑了约10,000 Token。
部署脚本:5分钟
# Codex写部署脚本 > 写一个bash脚本,用于: 1. 安装新增的npm依赖 2. 创建一个cron任务,每天凌晨清理24小时前的导出临时文件 3. 重启服务
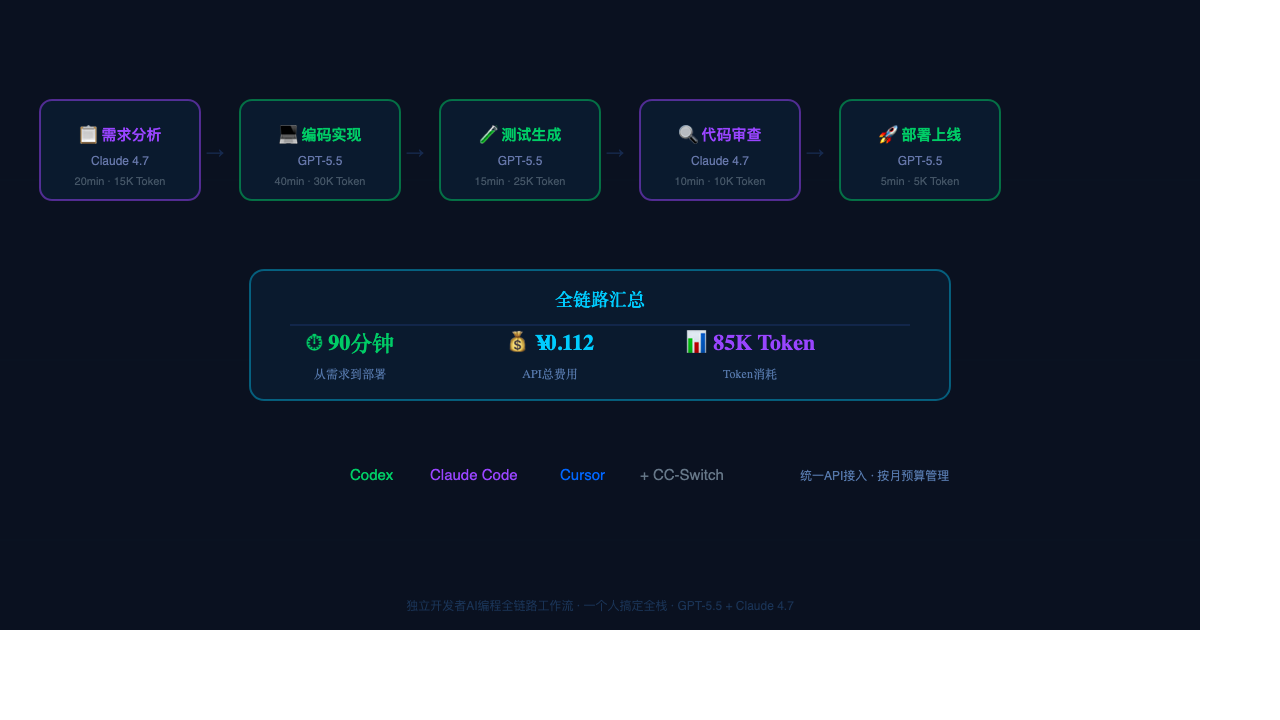
全链路Token消耗汇总
| 环节 | 工具/模型 | Token | 时间 | 费用 |
|---|---|---|---|---|
| 需求分析+设计 | Claude Code + Claude 4.7 | 15,000 | 20分钟 | ¥0.037 |
| 编码实现 | Codex + GPT-5.5 | 30,000 | 40分钟 | ¥0.025 |
| 测试生成 | Codex + GPT-5.5 | 25,000 | 15分钟 | ¥0.021 |
| 代码审查 | Claude Code + Claude 4.7 | 10,000 | 10分钟 | ¥0.025 |
| 部署脚本 | Codex + GPT-5.5 | 5,000 | 5分钟 | ¥0.004 |
| 合计 | 85,000 | 90分钟 | ¥0.112 |
一个完整功能,从需求到部署,Token费用一毛一分二。
没有AI工具的情况下,这个功能我至少需要半天(4小时)。有了AI全链路支持,90分钟搞定——效率提升了约2.7倍。而API成本是零点一一二元。
三、独立开发者的API预算管理
独立开发者最大的成本不是工具,是API Token。管理好预算的三个关键:
3.1 按项目分令牌
在API聚合平台上为每个项目创建独立的API令牌:
| 令牌 | 用途 | 月预算 |
|---|---|---|
| project-ecommerce | 电商后台项目 | 300 Token额度 |
| project-blog | 博客系统 | 200 Token额度 |
| agent-automation | 自动化脚本 | 100 Token额度 |
每个令牌独立追踪消耗,哪个项目吃Token最多一目了然。控制台中查看日消耗和月消耗曲线,不会出现「月底发现花超了」的情况。
3.2 模型切换策略
GPT-5.5的Token单价约Claude 4.7的三分之一。在工作流中把日常编码分给GPT-5.5,把深度分析分给Claude 4.7,自然达到了成本平衡。
通过CC-Switch可以在本地一键切换模型,所有工具同步生效。
3.3 定期审计消耗
每周花5分钟看一下API消耗报告,关注三个指标:
- 总Token消耗趋势:是上升还是稳定?上升了是因为新增了工具还是某个任务异常?
- 各模型消耗占比:GPT-5.5和Claude 4.7的比例是否合理?
- 单次请求Token异常:有没有某一次请求消耗了异常高的Token(可能是死循环或提示词问题)
四、高效工作流的几个原则
- 先设计,再实施:Claude Code把设计做透,Codex照着实施。不要在实施中重新设计,那是最浪费Token的做法。
- 一个功能一个会话:不要把多个功能塞进同一个对话。上下文膨胀会导致后续每个请求的Token消耗暴涨。
- 定期清空上下文:功能完成后用 /clear 清空对话,Token账单会好看很多。
- 精确指令比泛指令省Token:说清楚文件名、函数名、接口格式,AI不用猜。
- 代码审查放在最后:所有代码写完再一次性审查,比边写边审省Token且更全面。
五、总结
独立开发者的AI编程工作流不是「选一个工具用到黑」,而是按环节选工具、按任务配模型、按项目管Token。
我的核心公式:需求/设计用Claude Code + Claude 4.7(推理深),编码/测试/部署用Codex + GPT-5.5(执行快),编辑器日常用Cursor(补全爽)。所有工具从同一个API接入平台获取凭证,共用一份预算。
API接入也非常简单:在 api.bblabu.cn 注册、创建令牌、填到工具里,五分钟搞定。然后就可以把全部精力放在写代码上,Token费用交给聚合平台的低价去消化。
一个人的团队也能有全栈产出,核心不在于你多强,在于你用AI工具的方式多聪明。
本文链接:https://www.kkkliao.cn/?id=3938 转载需授权!
版权声明:本文由廖万里的博客发布,如需转载请注明出处。









