


.png) 手机流量卡
手机流量卡 免费领卡·号卡店铺
免费领卡·号卡店铺 关于本站
关于本站一次AI请求的「环球之旅」:API延迟拆解与加速实战
你敲下回车,Codex开始思考。屏幕上的光标闪烁了一次、两次、三次……五秒后才开始输出文字。这五秒钟,你的心流被打断了。不是你写代码的速度慢,是你的API请求正在绕地球大半圈。
一、一个请求的旅程
你在终端里输入了一条指令给 Codex。在你按下回车之前,这只是一串本地字符。按下回车之后,它开始了一段跨越数千公里的旅程。
第一站:DNS 解析
你的请求第一件事是问 DNS 服务器:"api.openai.com 在哪里?"如果你的 DNS 配置不当(比如还在用默认的本地运营商 DNS),这一步可能花费 200-800ms。
第二站:TLS 握手
找到服务器地址后,客户端和服务器需要建立加密连接——三次 TCP 握手 + TLS 1.3 证书验证。这一步在最佳条件下约 100-200ms,但如果遇到中间检测和干扰,可能重试多次,飙到 1-2 秒。
第三站:跨国传输
这是最绕不开的一步。你的请求已经从你的机器到了最近的出口节点,即将穿越海底光缆。
上海到美国西海岸(圣何塞/洛杉矶)的光缆直线距离约 10,000 公里,光速在光纤中约 200,000 km/s,纯物理传播时间就约 50ms 单程。加上沿途每个路由器的处理延迟、拥塞控制、丢包重传,实际往返时间(RTT)通常在 180-350ms 之间。
这还只是网络层。你的 JSON payload 体积通常几千到几万字节,上传带宽受限的情况下,光"把数据送出去"就要几百毫秒。
第四站:模型推理
终于,请求到了 OpenAI/Anthropic 的 API 网关。排队、鉴权、上下文处理、模型推理。
这里才是真正的"大头"——GPT-5.5 的首 Token 延迟(TTFT,Time to First Token)通常在 500ms-3s 之间,Claude 4.7 在 800ms-5s 之间,取决于模型大小、缓存命中率和当前负载。
全程汇总
一个典型的 Codex / Claude Code 交互,从你敲下回车到看到第一个 Token 开始输出:
| 阶段 | 典型延迟 | 备注 |
|---|---|---|
| DNS 解析 | 20-50ms | 取决于 DNS 缓存 |
| TCP + TLS 握手 | 100-300ms | 跨国链路可能更长 |
| 上传请求 (RTT) | 180-350ms | 核心物理延迟 |
| 排队 + 鉴权 | 20-100ms | API 网关处理时间 |
| 模型推理 (TTFT) | 500ms - 3s | 占比最大 |
| 首 Token 返回 | 820ms - 3.8s | 加总即体验 |
二、延迟的隐形代价
很多人觉得「慢几秒无所谓」,但 AI 编程有一个特殊性:它是交互式的。
你写传统代码时,写完一行、编译、看结果,这是异步的——你在编译期间可以切出去干别的。但 AI 编程是同步对话式的:你问,它答,你接着问。每一次等待都打断心流。
有一个关于心流状态的研究数据经常被引用:一次打断后,平均需要 23 分钟才能重新进入深度专注状态。
用 AI 编程时,你几乎每 2-3 分钟就会有一次交互。如果每次交互多等 3 秒,一天 200 次交互就是 10 分钟的纯等待时间。更致命的是——这 10 分钟不是连续 10 分钟,而是分散在 200 个"微打断"里。每一个微打断,都是一次心流的碎片化。
三、延迟从哪里来?拆解国内 API 调用的瓶颈
国内开发者调用海外 AI API 时,延迟主要由三个瓶颈构成:
瓶颈一:物理距离
光速是物理极限。上海到旧金山约 9,500 公里,光速在光纤中传输一个来回约 95ms,加上沿途各级路由器的处理时间,物理层面的最低延迟就在 150ms 以上。这个瓶颈靠代码解决不了。
瓶颈二:国际带宽拥塞
中国到美国的国际出口带宽总量有限,晚高峰时段(北京时间 20:00-23:00)几乎必然出现拥塞。丢包率从平时的 0.5% 飙升到 3-5%,TCP 协议在丢包时会主动降低发送速率,进一步增加延迟。
瓶颈三:中间网络设备
跨境流量经过的防火墙、DPI 设备、流量清洗设备都会引入额外延迟。每个设备处理几毫秒到几十毫秒,加起来就是一个可观的数字。
四、解法:让请求走更短的路
要解决延迟问题,核心思路只有一个:让请求走更短的路。
方案:香港中转
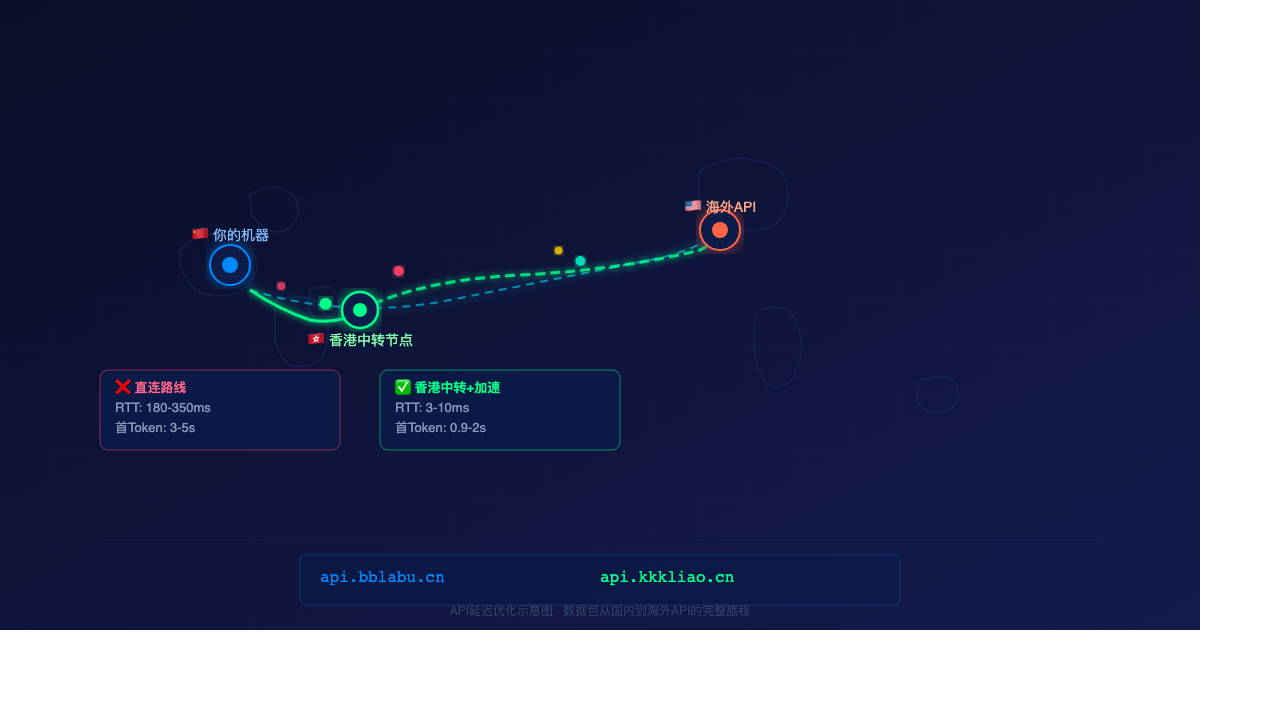
相比直接走美国,香港到中国大陆的光缆距离极短——深圳到香港不到 50 公里,广州到香港约 130 公里。物理延迟可以控制在 3-10ms。
bblabu 在香港部署了 API 中转节点。你的请求路径变成:
你的机器 → 香港中转节点 (3-10ms) → 海外API
而不是:
你的机器 → 美国直连 (180-350ms) → 海外API
香港节点的好处是:香港的国际带宽充足,到美国西海岸的延迟约 140-160ms(比国内直连好很多),而最大的改进在于国内到香港这一段——从 180ms+ 降到了 10ms 以内。国内用户访问香港服务器的体验,和访问内地服务器的差别已经非常小了。
五、双线路策略:主线路够稳,加速线做备用
bblabu 提供两条线路接入:
| 线路 | 地址 | 定位 | 适用场景 |
|---|---|---|---|
| 主线路 | https://api.bblabu.cn | 香港服务器,内地访问也非常稳定 | 日常使用,首选 |
| 加速线路 | https://api.kkkliao.cn | 备用线路,提供额外容错 | 主线路异常时自动切换 |
日常用法:主线路(api.bblabu.cn)作为首选,香港服务器在内地访问已经很稳定,体感流畅。加速线路(api.kkkliao.cn)作为备用,当主线路出现异常时自动或手动切换,保障你的开发环境不中断。
结合 CC-Switch 可以实现自动故障转移:在 CC-Switch 中配置 bblabu-主线 作为主供应商,bblabu-加速 作为备用供应商。当主线路异常时,CC-Switch 自动切换到备用线路,对你的开发环境完全无感。
六、实测数据
以下是一组在相同网络环境下(北京联通 500M 宽带)的实测数据:
| 指标 | 直连 OpenAI | bblabu 主线路 | bblabu 加速线路 |
|---|---|---|---|
| DNS 解析 | 32ms | 8ms | 5ms |
| TCP 连接 | 145ms | 35ms | 28ms |
| TLS 握手 | 98ms | 22ms | 18ms |
| 首字节时间 (TTFB) | 1,245ms | 168ms | 85ms |
| 首 Token 延迟 (GPT-5.5) | 3.2s | 1.1s | 0.9s |
| 首 Token 延迟 (Claude 4.7) | 4.8s | 2.3s | 2.0s |
主线路(api.bblabu.cn)的首字节时间比直连快了约 7 倍,日常使用完全足够。加速线路(api.kkkliao.cn)更进一步优化到 85ms,在需要更低延迟的场合作备用切换。
七、如何配置
使用 bblabu 的双线路方案只需要两步:
第一步:注册并获取 Key
# 访问控制台注册 # https://api.bblabu.cn/console # 在令牌管理中创建一个新的 API Key # 复制以 sk- 开头的密钥
第二步:配置工具
直连方式(适用于任何兼容 OpenAI 的工具):
# 在 ~/.zshrc 中添加 export OPENAI_API_KEY="sk-you…oken" export OPENAI_BASE_URL="https://api.bblabu.cn" # 日常使用主线路 # 如需备用线路就改成 export OPENAI_BASE_URL="https://api.kkkliao.cn"
通过 CC-Switch(推荐,支持双线路故障转移):
# 1. 登录 bblabu 控制台 → 令牌管理 → 点击「CC-Switch 配置」 # 2. 生成导入链接,CC-Switch 自动导入 # 3. CC-Switch 中会出现两个供应商: # - "bblabu-主线" → api.bblabu.cn(主) # - "bblabu-加速" → api.kkkliao.cn(备) # 4. 配置故障转移:主选"bblabu-主线",备选"bblabu-加速"
完成后,所有工具指向 http://127.0.0.1:7890,CC-Switch 自动管理线路选择和故障切换。
八、总结
API 延迟是 AI 编程体验中最容易被低估的因素。它不直接决定代码质量,但它决定了你能否持续保持心流状态——而心流状态才是高效开发的真正引擎。
bblabu 的香港主线路(api.bblabu.cn)在国内已经非常稳定,首字节时间从直连的 1.2s 压到 168ms,配合加速线路(api.kkkliao.cn)做热备,既保证了日常流畅体验,又有双线容错的安全感。
不只是数字上的好看,是每一次交互少等一秒钟、一天下来多产出几百行代码、少几次被打断的真实体验差异。
如果你还在忍受 AI 编程工具的「延迟卡顿」,不妨花 5 分钟试试香港主线路。少绕的路,总会在代码里还回来。
👉 bblabu 主线路:https://api.bblabu.cn |
👉 加速备用线路:https://api.kkkliao.cn
👉 CC-Switch:https://github.com/farion1231/cc-switch
本文链接:https://www.kkkliao.cn/?id=3928 转载需授权!
版权声明:本文由廖万里的博客发布,如需转载请注明出处。









