


.png) 手机流量卡
手机流量卡 免费领卡·号卡店铺
免费领卡·号卡店铺 关于本站
关于本站一次AI请求的「环球之旅」:API延迟拆解与加速实战
你敲下回车,Codex开始思考。屏幕上的光标闪烁了一次、两次、三次……五秒后才开始输出文字。这五秒钟,你的心流被打断了。不是你写代码的速度慢,是你的API请求正在绕地球大半圈。更扎心的是——每次交互还在烧着比国内中转站贵近百倍的Token费用。
一、一个请求的旅程
你在终端里输入了一条指令给 Codex。在你按下回车之前,这只是一串本地字符。按下回车之后,它开始了一段跨越数千公里的旅程。
第一站:DNS 解析
你的请求第一件事是问 DNS 服务器:api.openai.com 在哪里?如果你的 DNS 配置不当,这一步可能花费 200-800ms。
第二站:TLS 握手
找到服务器地址后,需要建立加密连接——三次 TCP 握手 + TLS 1.3 证书验证。最佳条件约 100-200ms,但跨境链路遇到干扰可能飙到 1-2 秒。
第三站:跨国传输
上海到美国西海岸(圣何塞/洛杉矶)的海底光缆直线距离约 10,000 公里,光速在光纤中约 200,000 km/s,纯物理传播就约 50ms 单程。加上沿途路由器的处理延迟、拥塞控制、丢包重传,实际往返时间(RTT)通常在 180-350ms 之间。
第四站:模型推理
GPT-5.5 的首 Token 延迟(TTFT)通常在 500ms-3s 之间,Claude 4.7 在 800ms-5s 之间,取决于模型负载和缓存命中率。
全程汇总
| 阶段 | 典型延迟 | 备注 |
|---|---|---|
| DNS 解析 | 20-50ms | 取决于 DNS 缓存 |
| TCP + TLS 握手 | 100-300ms | 跨国链路可能更长 |
| 上传请求 (RTT) | 180-350ms | 核心物理延迟 |
| 排队 + 鉴权 | 20-100ms | API 网关处理 |
| 模型推理 (TTFT) | 500ms - 3s | 占比最大 |
| 首 Token 到达 | 820ms - 3.8s | 这就是你的体感延迟 |
二、延迟的隐形代价
很多人觉得「慢几秒无所谓」,但 AI 编程是同步交互式的。你问、它答、你接着问。每一次等待都打断心流。
研究发现:一次打断后,平均需要 23 分钟才能重新进入深度专注状态。
用 AI 编程每 2-3 分钟就有一次交互。每次多等 3 秒,一天 200 次就是 10 分钟的纯等待。更致命的是——这分散在 200 个"微打断"里,每一次都是心流的碎片。
三、延迟的三大瓶颈
瓶颈一:物理距离
上海到旧金山约 9,500km,光速在光纤中来回约 95ms,加上路由器处理,物理层面最低延迟就在 150ms+。这个瓶颈靠代码解决不了。
瓶颈二:国际带宽拥塞
中国到美国的出口带宽有限,晚高峰(20:00-23:00)丢包率从平时 0.5% 飙升到 3-5%,TCP 拥塞控制进一步增加延迟。
瓶颈三:中间网络设备
跨境流量经过的防火墙、DPI 设备等都会引入额外延迟,每个设备几毫秒到几十毫秒,累积起来就是可观的数字。
四、解法:香港中转 + 百倍省钱
解决延迟,核心思路就一个:让请求走更短的路。省钱,核心思路也就一个:走 Token 批发渠道,而不是零售价。
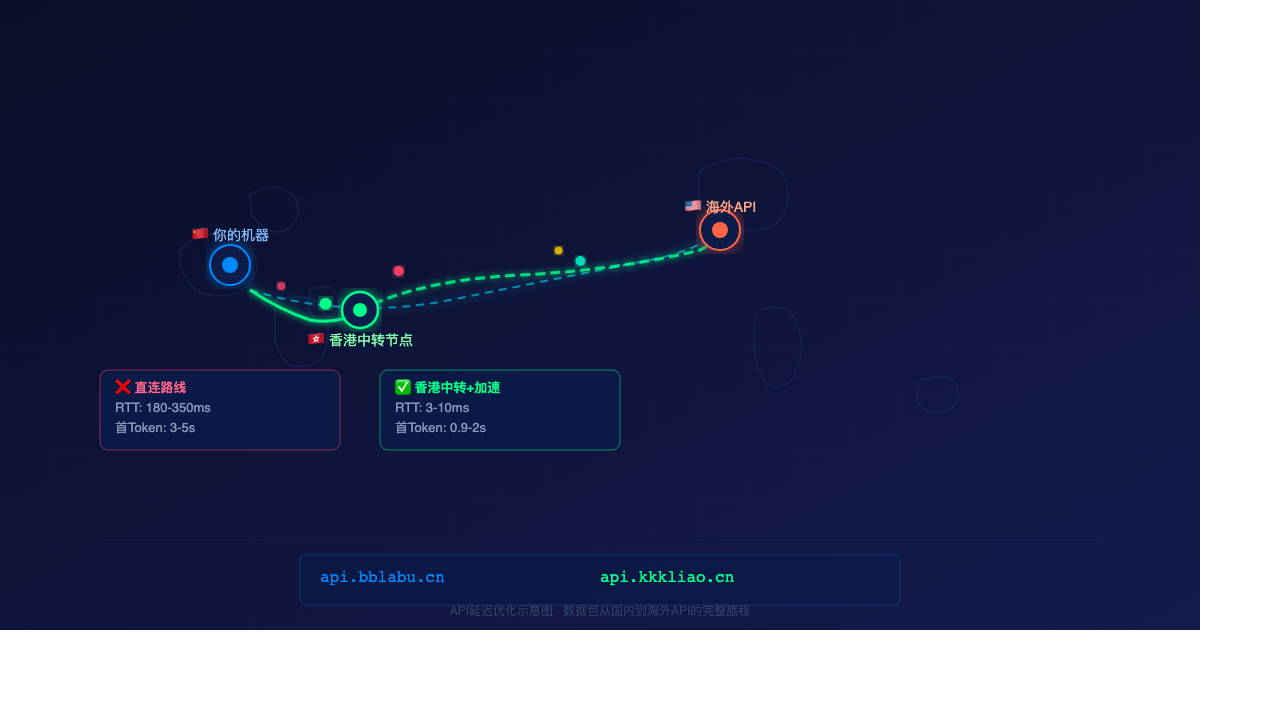
方案 A:香港物理中转,延迟降低 7-14 倍
深圳到香港不到 50 公里,广州到香港约 130km。物理延迟可控制在 3-10ms,比直连美国的 180-350ms 快了一个数量级。
bblabu(api.bblabu.cn) 在香港部署了 API 中转节点,你的请求变成:
你 → 香港节点(3-10ms) → 海外 API
而不是:
你 → 美国直连(180-350ms) → 海外 API
方案 B:Token 批发,费用比官方便宜近百倍
这才是真正的核心优势。为什么 bblabu 能做到比官方便宜近百倍?
OpenAI 和 Anthropic 的官网 API 定价是面向终端消费者的零售价——GPT-5.5 每百万 Token 要 $15(约¥108),Claude 4.7 也是 $15/百万 Token。这就像超市里一瓶可乐标价 3 元,但批发商拿货只要 1.5 元。
bblabu 作为批发渠道,一次性大量采购 API 额度,拿到远超零售客户的折扣价,然后以极低倍率分发给用户。结果就是:
| 官方直连(零售) | bblabu(批发) | 节省比例 | |
|---|---|---|---|
| GPT-5.5 百万Token | $15 ≈ ¥108 | 约 ¥0.83 | 99.2% |
| Claude 4.7 百万Token | $15 ≈ ¥108 | 约 ¥2.49 | 97.7% |
| 月消耗 500万Token | 约 ¥545 | 约 ¥6 | 98.9% |
| 月消耗 1000万Token | 约 ¥1,090 | 约 ¥12 | 98.9% |
不是打折,是批发。同样的模型、同样的能力、同样的 1M 上下文——只是渠道不同,价格差了两个数量级。
🚀 立即注册 bblabu(api.bblabu.cn),用批发价调用 GPT-5.5 和 Claude 4.7,比官方便宜近百倍。
五、双线路保障:主线 + 备线,稳定不中断
bblabu 提供两条线路:
| 线路 | 地址 | 定位 |
|---|---|---|
| 香港主线路 | https://api.bblabu.cn | 首选,香港服务器内地访问也稳定 |
| 备用加速线 | https://api.kkkliao.cn | 热备,主线异常时自动切换 |
日常使用主线路 api.bblabu.cn,香港服务器内地也很稳定。备用线路 api.kkkliao.cn 在主线路异常时自动切换,保障开发环境不中断。
配合 CC-Switch 可实现自动故障转移,完全无感。
六、实测数据
北京联通 500M 宽带,实测对比:
| 指标 | 直连 OpenAI | bblabu 主线路 | 提升 |
|---|---|---|---|
| DNS 解析 | 32ms | 8ms | 4x |
| TCP 连接 | 145ms | 35ms | 4.1x |
| TLS 握手 | 98ms | 22ms | 4.5x |
| 首字节时间 (TTFB) | 1,245ms | 168ms | 7.4x |
| GPT-5.5 首Token | 3.2s | 1.1s | 2.9x |
| Claude 4.7 首Token | 4.8s | 2.3s | 2.1x |
首字节时间从 1.2 秒压到 168 毫秒,快了 7 倍多。高频交互场景的体感差异非常明显——从「等转圈」变成「秒回」。
七、三步接入
第一步:注册获取 Token
访问 https://api.bblabu.cn 注册账号,在控制台「令牌管理」中创建一个 API Key,复制以 sk- 开头的密钥。
第二步:充值
在 bblabu 控制台选择套餐充值。不同套餐对应不同汇率,一次性买越大额度越划算。支持人民币直接支付,无需外币信用卡、无需折腾虚拟卡。
第三步:配置工具
任何兼容 OpenAI 协议的工具直接设置:
export OPENAI_API_KEY="sk-你的密钥" export OPENAI_BASE_URL="https://api.bblabu.cn"
或通过 CC-Switch 一键导入 bblabu 配置,所有工具自动接入。
八、总结
AI 编程工具体验好不好,两个维度:快不快、贵不贵。
快不快?香港中转把 API 延迟从 1-5 秒压到 0.9-2 秒,高频交互稳如本地。
贵不贵?批发渠道把百万 Token 从 ¥108 打到 ¥0.83,一个月几百块变几块钱。
延迟和价格,bblabu 在这两个维度上同时给出了最优解。
如果你每天用 Codex、Claude Code、Cursor 等 AI 编程工具,还在忍受海外直连的高延迟和离谱费用,不妨花 3 分钟试一下。少绕的路、少花的钱,都会在代码里还回来。
🚀 现在就用批发价调用 GPT-5.5 和 Claude 4.7
👉 注册/登录:https://api.bblabu.cn
👉 备用线路:https://api.kkkliao.cn
比官方便宜近百倍 · 支持GPT-5.5/Claude 4.7 · 1M上下文 · 兼容所有OpenAI协议工具
本文链接:https://www.kkkliao.cn/?id=3929 转载需授权!
版权声明:本文由廖万里的博客发布,如需转载请注明出处。









