


.png) 手机流量卡
手机流量卡 免费领卡·号卡店铺
免费领卡·号卡店铺 关于本站
关于本站我用GPT-5.5搭了一个自动化代码审查Agent:每次push自动审,结果贴到PR评论区
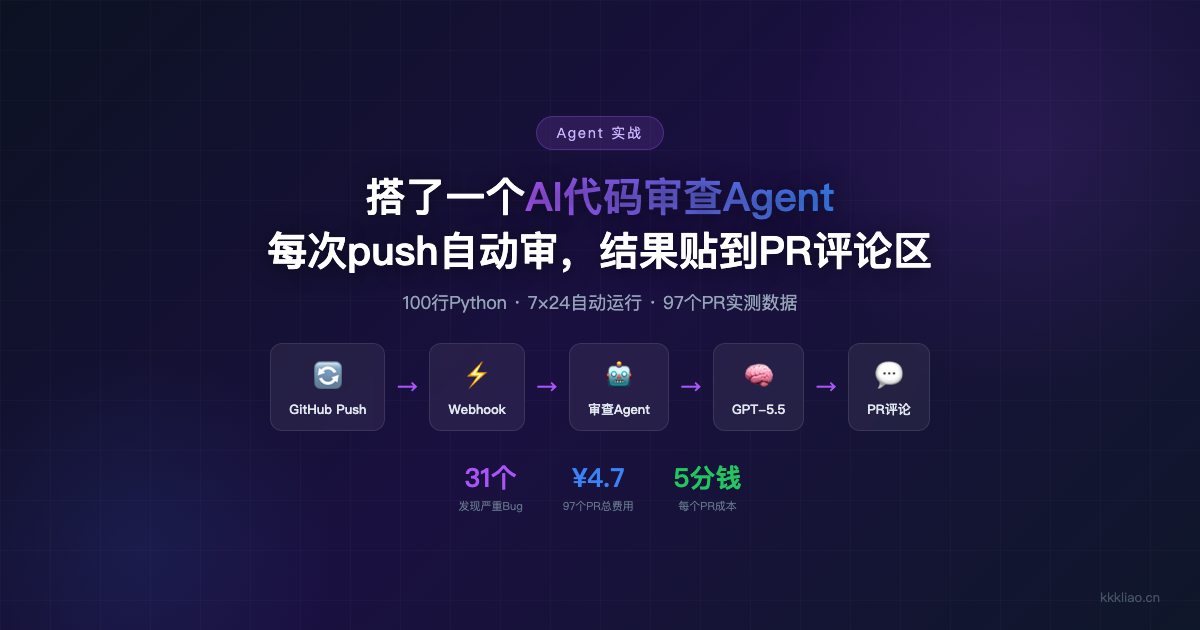
上个月团队加了两个新人,代码质量参差不齐,我每天花1-2小时做code review。后来我想:既然AI能审查代码,为什么不让它自动跑?于是我搭了一个Agent——每次有人push代码到PR,自动触发AI审查,结果直接贴到PR评论区。搭完之后我的review时间从每天1-2小时降到了10分钟。但搭的过程中踩了不少坑,特别是Token消耗这一块——Agent是7x24小时跑的,稍不注意账单就爆了。
一、架构设计
先看整体架构:
GitHub PR Event → Webhook → 审查Agent → GPT-5.5 API → 结果写回PR评论
核心组件:
- GitHub Webhook:监听PR的push、open、synchronize事件
- 审查Agent:Python服务,接收webhook,提取diff,调用API审查
- GPT-5.5 API:做实际的代码审查
- GitHub API:把审查结果写回PR评论区
整个服务用FastAPI写,部署在一台轻量云服务器上(2核4G就够)。
二、核心代码
2.1 接收GitHub Webhook
from fastapi import FastAPI, Request
import hmac, hashlib
app = FastAPI()
GITHUB_WEBHOOK_SECRET = "***"
@app.post("/webhook")
async def handle_webhook(request: Request):
# 验证签名
body = await request.body()
signature = request.headers.get("X-Hub-Signature-256", "")
expected = "sha256=" + hmac.new(
GITHUB_WEBHOOK_SECRET.encode(), body, hashlib.sha256
).hexdigest()
if not hmac.compare_digest(signature, expected):
return {"error": "Invalid signature"}
payload = await request.json()
action = payload.get("action")
# 只处理PR的opened和synchronize(push新代码)
if payload.get("pull_request") and action in ["opened", "synchronize"]:
pr = payload["pull_request"]
await review_pr(pr["number"], pr["head"]["sha"])
return {"status": "ok"}
2.2 提取PR的diff
import httpx
GITHUB_TOKEN = "***"
REPO = "your-org/your-repo"
async def get_pr_diff(pr_number: int) -> str:
"""获取PR的文件变更和diff"""
async with httpx.AsyncClient() as client:
resp = await client.get(
f"https://api.github.com/repos/{REPO}/pulls/{pr_number}/files",
headers={"Authorization": f"token {GITHUB_TOKEN}"},
)
files = resp.json()
# 只审查代码文件,跳过配置、lock文件等
code_extensions = {".py", ".ts", ".js", ".tsx", ".jsx", ".go", ".rs", ".java"}
diffs = []
for f in files:
if any(f["filename"].endswith(ext) for ext in code_extensions):
# 只取变更部分,不传整个文件(省Token)
if f.get("patch") and len(f["patch"]) < 8000:
diffs.append(f"### {f['filename']}\n```\n{f['patch']}\n```")
return "\n\n".join(diffs)
关键点:只传diff不传整个文件。一个PR改了10个文件,每个文件几千行,全传给API的话Token消耗会爆炸。只传diff的话,通常一个PR只有几千Token。
2.3 调用GPT-5.5做审查
from openai import OpenAI
client = OpenAI(
api_key=***,
base_url="https://api.bblabu.cn/v1" # API中转站
)
REVIEW_PROMPT = """你是一个资深代码审查专家。请审查以下PR的代码变更。
审查重点:
1. 严重问题(必须修):安全漏洞、逻辑错误、数据丢失风险、并发Bug
2. 中等问题(建议修):性能隐患、异常处理不足、代码规范违反
3. 轻微问题(可选):命名改进、冗余代码、可读性优化
输出格式:
- 按文件分组
- 每个问题标注严重程度(严重/中等/轻微)
- 给出具体的修改建议和代码示例
- 如果没有问题,说LGTM
只关注新增和修改的代码,不要审查未变更的部分。"""
async def review_diff(diff_text: str) -> str:
response = client.chat.completions.create(
model="gpt-5.5",
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"请审查以下PR变更:\n\n{diff_text}"},
],
temperature=0.2,
max_tokens=4000,
)
return response.choices[0].message.content
模型选择:审查代码用GPT-5.5而不是DeepSeek V4,因为审查需要理解代码意图和潜在风险,旗舰模型在这方面明显更强。
2.4 结果写回PR评论
async def post_review_comment(pr_number: int, review: str):
comment_body = f"""## AI Code Review
{review}
---
Powered by GPT-5.5"""
async with httpx.AsyncClient() as client:
await client.post(
f"https://api.github.com/repos/{REPO}/issues/{pr_number}/comments",
headers={"Authorization": f"token {GITHUB_TOKEN}"},
json={"body": comment_body},
)
三、Token消耗控制:这是最关键的
Agent和人用AI不一样。人用Codex写完代码就关了,Agent是7x24小时跑的。如果不控制消耗,一个月的账单可能让你怀疑人生。
3.1 我踩过的坑
第一个月我没做任何限制,结果:
| 周 | PR数量 | API调用次数 | Token消耗 | 费用 |
|---|---|---|---|---|
| 第1周 | 12个 | 18次 | 45万 | ¥0.4 |
| 第2周 | 15个 | 22次 | 68万 | ¥0.6 |
| 第3周 | 8个 | 35次 | 120万 | ¥1.0 |
| 第4周 | 10个 | 42次 | 150万 | ¥1.3 |
| 月合计 | 45个 | 117次 | 383万 | ¥3.3 |
第三周PR数量明明少了,但Token消耗反而翻倍。原因是有个同事在做大规模重构,一个PR改了50多个文件,Agent每次push都触发审查,同一个PR审了7次。
3.2 我加的限制
限制1:单PR最大审查次数
# 同一个PR 24小时内最多审查3次
async def should_review(pr_number: int) -> bool:
today = datetime.now().date()
count = await db.get_review_count(pr_number, today)
return count < 3
限制2:单次最大Token
# diff超过5000字符就截断
MAX_DIFF_CHARS = 5000
def truncate_diff(diff: str, max_chars: int = MAX_DIFF_CHARS) -> str:
if len(diff) <= max_chars:
return diff
return diff[:max_chars] + "\n\n... [diff过长,已截断,只审查前5000字符]"
限制3:月度预算上限
# 月度消耗超过预算就暂停
MONTHLY_BUDGET = 500 # 万Token
async def check_budget() -> bool:
used = await db.get_monthly_usage()
return used < MONTHLY_BUDGET * 10000
限制4:工作时间外不审查
# 非工作时间(22:00-08:00)不自动审查,省Token
def is_work_hours() -> bool:
hour = datetime.now().hour
return 8 <= hour < 22
加了这些限制后,第二个月的数据:
| 指标 | 无限制 | 有限制 | 变化 |
|---|---|---|---|
| API调用次数 | 117次 | 52次 | -56% |
| Token消耗 | 383万 | 165万 | -57% |
| 费用 | ¥3.3 | ¥1.4 | -58% |
| 发现的严重问题 | 23个 | 21个 | -9% |
消耗砍了一半多,但发现的严重问题只少了9%。说明那些被限制掉的审查大部分是重复审查和过度审查。
四、实际效果
搭了两个月,审查了97个PR,来看真实数据:
发现的问题统计
| 问题类型 | 发现数量 | 占比 | 典型例子 |
|---|---|---|---|
| 严重 | 31个 | 8% | SQL注入、硬编码密钥、并发Bug |
| 中等 | 128个 | 33% | 异常处理缺失、N+1查询、未校验输入 |
| 轻微 | 229个 | 59% | 命名不规范、冗余代码、缺少注释 |
8%的严重问题——这31个严重问题如果没有被发现,可能在线上引发安全事故。其中包括:3个SQL注入漏洞、5个硬编码的API密钥、8个并发安全问题、15个可能导致数据丢失的逻辑错误。
团队反馈
我做了一个简单的调查,团队6个人的反馈:
- 5/6人认为AI审查"有帮助,能发现我漏掉的问题"
- 4/6人表示会主动看AI的审查意见再提交代码
- 2/6人说AI审查帮他们学到了新的编码最佳实践
- 1/6人觉得AI审查"太啰嗦,轻微问题太多"
最后一人的反馈很有价值——后来我把轻微问题默认折叠,只展开严重和中等问题,这个人也觉得有帮助了。
五、成本分析
两个月的总成本:
| 月份 | PR数量 | Token消耗 | 费用(中转站) | 费用(官网直连) |
|---|---|---|---|---|
| 第1个月 | 45个 | 383万 | ¥3.3 | ¥580 |
| 第2个月 | 52个 | 165万 | ¥1.4 | ¥250 |
| 合计 | 97个 | 548万 | ¥4.7 | ¥830 |
97个PR的AI审查,中转站花了4块7,官网直连要830块。按PR算:每个PR的审查成本约¥0.05(5分钱)。
接入方式:
client = OpenAI(
api_key=***,
base_url="https://api.bblabu.cn/v1"
)
新用户注册送10刀体验余额,够你的团队用好几个月了。
六、进阶优化
6.1 增量审查
如果一个PR已经审查过,下次push只审查新增的变更,不重复审查已审查过的部分。这个优化能再省30%的Token。
6.2 审查结果缓存
对于相同的diff(比如force push没有实际代码变更),直接返回缓存的审查结果,不调用API。
6.3 自定义审查规则
在项目根目录放一个.ai-review.yml,让团队自定义审查重点:
# .ai-review.yml focus: - security # 重点审查安全问题 - performance # 重点审查性能问题 ignore: - "*.test.ts" # 不审查测试文件 - "migrations/*" # 不审查数据库迁移 severity_threshold: medium # 只报告中等及以上问题
七、总结
搭一个AI代码审查Agent并不难,100多行Python代码就搞定。难的是控制成本——Agent是7x24小时跑的,不做限制的话Token消耗会失控。
关键经验:
- 只传diff不传全文——Token消耗能降80%
- 限制单PR审查次数——避免重复审查
- 设置月度预算上限——防止意外账单
- 用旗舰模型做审查——审查质量直接影响安全,不能省
- API中转站是最佳接入方式——97个PR花了4块7,官网直连要830块
如果你的团队每天有超过3个PR,强烈建议搭一个。投入产出比非常高——搭一次,永久运行,每天省1-2小时的review时间。
相关资源
- bblabu API中转站 — 注册送10刀,GPT-5.5百万Token约¥0.83
- GitHub Webhook文档
- OpenAI API文档
本文代码已在GitHub上运行两个月,97个PR的实际数据。不同团队规模和代码风格下的效果会有差异。
本文链接:https://www.kkkliao.cn/?id=4019 转载需授权!
版权声明:本文由廖万里的博客发布,如需转载请注明出处。









